 音视频处理库
音视频处理库
tess4j 是JAVA对Tesseract OCR API的封装。
一般来说windows上可以正常运行,但是如果部署到Linux上的话,可能会出现确实少库的问题
大概是因为jar下不含Linux环境所需要的so库。
Windows: dll
Linux: so
下面记录下在Linux上部署 Tesseract
# 开始
Tesseract 编译需要 Leptonica,所以需要先安装Leptonica
Tesseract 地址 (opens new window)
Leptonica 地址 (opens new window)
注意
安装时务必注意版本,否则Tesseract有可能编译报错:Leptonica xxx or higher is required
以下所以操作均在root用户下进行,非root用户记得升权
# 安装 Leptonica
下载安装包解压,进入文件目录执行
./configure
make
make install
ldconfig
# 安装 Tesseract
下载安装包解压,进入文件目录执行
./autogen.sh
#此时版本不对将会报错
./configure
make
make install
ldconfig
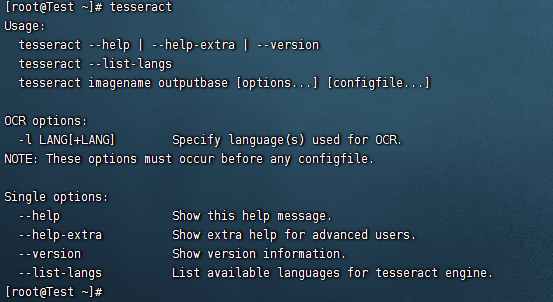
# 验证
tesseract
如下即说明安装成功
# JAVA中使用
# 引入
# Maven
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<!-- 注意修改 ${tess4j.version} 为自己的版本-->
<version>${tess4j.version}</version>
</dependency>
# Gradle
#注意修改 ${tess4j.version} 为自己的版本
implementation group: 'net.sourceforge.tess4j', name: 'tess4j', version: '${tess4j.version}'
# 使用
# 简单示例
public class TextOcrUtil {
@SneakyThrows
public static String doOcr(File file) throws IOException {
//兼容Linx,指向自己的so库路径
System.setProperty("jna.library.path", "/usr/local/lib");
ITesseract instance = new Tesseract();
//OcrConfig.TESS_DATA 为语言包路径,例如:/home/java/app/tessdata
instance.setDatapath(OcrConfig.TESS_DATA);
//语言包名字
instance.setLanguage("chi_sim");
// 设置识别引擎
instance.setOcrEngineMode(1);
// 读取文件
BufferedImage image = ImageIO.read(file);
String orcResult = instance.doOCR(image);
log.info("识别结果:{}",orcResult);
return orcResult;
}
}
# 版本问题解决
1. 查看/usr/local/include/leptonica 路径下是否有 .h文件
2. 查看 /usr/local/lib 下 liblept 开头文件
3. pkg-config 是否正常,没有请安装
yum install pkg-config
4. 确保 /usr/local/lib/pkgconfig/ 文件夹下有 lept.pc 以及 tesseract.pc 文件
5. 修改 /etc/profile
vi /etc/profile
添加如下内容
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
export LIBLEPT_HEADERSDIR=/usr/local/include
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
6. 使配置生效
source /etc/profile
7. 重新编译 tesseract
./autogen.sh
./configure --with-extra-includes=/usr/local/include --with-extra-libraries=/usr/local/lib
make
make install
上次更新: 2026/02/27, 03:03:58